Listen to this record
Announcing ResearchOS.
A first look at Tetsuwan’s first-of-its-kind automation platform.
New Interest Meets an Old Problem
It is difficult to imagine a future that feels more uncertain than the one we now share. This is especially true for our researchers, who face mounting pressure to publish, declining funding rates, and increasing experimental complexity. How must the tools of science evolve to overcome the challenges it faces? Many have speculated that artificial intelligence will have a formidable role in this evolution. Perhaps AI could help to ask better questions, pick out anomalies invisible to the human mind, or even automate the scientific method in its entirety. The most ambitious of these visions, autonomous science, seeks to marry AI with physical lab automation to achieve end-to-end, closed-loop science.
Both the more established field of lab automation and the more nascent field of autonomous discovery have both recently experienced dramatic growth as capital from Canada (Acceleration Consortium, 200M CA), the United States (Genesis Mission, 320M USD), and the United Kingdom (ARIA) has flooded in. Anthropic, OpenAI, and Google have all also entered the domain of autonomous discovery, as they seek to aim their models at perhaps their most consequential mission yet: expanding our knowledge of the natural world. Large rounds for startups seeking to automate discovery in the life sciences and material science have been raised, notably by Lila and Periodic Labs. This is a wonderful time for the space. Amid this excitement, autonomous science must not forget to ask itself the difficult questions that will define its future. How will new automated tools actually impact research productivity? How will these tools make science more accessible, affordable, and reproducible? How does this space turn its in silico potential into material success?
Firstly, it must confront a difficult truth. The bottleneck to progress in the fields that autonomous science seeks to affect, such as the life sciences and materials science, is not knowledge work. Today, the life sciences has no shortage of hypotheses to test. It does not lack the capacity for more knowledge work, it lacks the capacity for more physical labor to synthesize and characterize the products of its knowledge work. This bottleneck also limits the further development of autonomous science. Models need more data, and more data means more physical labor, further exacerbating this bottleneck. New entrants into the field find this exceptionally surprising. How could this be true - why aren’t robotic systems used to automate the physical labor involved in experimentation and alleviate this bottleneck? It is time for new interest to meet an old problem.
High-Mix Automation
The question “Why does a physical labor bottleneck exist in the life sciences despite the existence of automated tooling?” is one of the first that we became interested in at Tetsuwan. The answer has shaped both the field of lab automation and its capabilities, as well as us, as a company. Today, the benefits of automation are limited to a specific class of tasks in the lab, most of which were already foreign to the tired hands that hold adjustable micropipettes. Lab automation is deployed most commonly in “low-mix, high-volume” environments. This means that the tasks that are being automated are similar to each other (“low-mix”), and that the task is being automated at a high volume. In contrast, a high-mix, low-volume environment would be something like a Subway: unique, custom sandwiches made for the few that wander in. Automated tooling capable of replacing the lab bench requires both variety and volume.
The former is where automation struggles. Yet, experimentation is by definition a process in which variability is deeply rooted in. How do we expand the limited domain of lab automation to automate the high-mix, variable work that scientists do at the bench?
The first (and most reasonable sounding) answer opines that the cost of hardware associated with lab automation, like liquid handlers, is just too expensive to groups where the alternative would be cheap physical labor. There are several issues with this hypothesis, but the most damning counterpoint comes from Opentron’s incredible work in making automation more affordable. Founded in 2011, Opentrons used 3D-printer manufacturing pipelines in Shenzhen to significantly drive down their cost of liquid handling platform relative to the incumbents. The group’s first commercial liquid handler, the OT-2, debuted in 2018 for just 4k. For context, even entry level liquid handlers range from 80-140k. Opentrons reduced the cost by nearly 20 fold. Yet, automation still couldn’t handle high-mix work, widespread adoption was not catalyzed, and the bottleneck of physical labor remains. Today, an OT-2 will run you ~16k. The OT-Flex, the successor to the OT-2, costs 30k.
The second common answer contends that it is the capabilities, not the cost, of automation hardware that restricts its use cases. Myriad form factors have been developed in the pursuit to succeed or augment the liquid handler, including novel gantry systems, humanoid arms, and even electrowetting-on-dialectrics systems capable of picoliter dispensing. A plethora of niche robots exist for the tasks that liquid handlers are not capable of: plate sealers, depeelers, tube decappers, and tilt modules, etc. A variety of solutions exist for the problem of tying together different pieces of hardware into one larger robot: Gingko’s RACs, Automata’s LinqBenches, autonomous mobile robots (AMRs), and even magnetic levitation track systems. Additional gizmos have not solved automation’s core problem: it is still incapable of the high-mix work that automation must expand into.
At Tetsuwan, we know that it’s not the cost of hardware, or its missing capabilities, that restrict the use cases for automation. Rather, it is the ability to even use the hardware. The process by which we use lab automation tools is called automation engineering.
Put as simply as possible, automation engineering is the process of translating implicit scientific knowledge to explicit commands. Of course, automation engineering is anything but simple. Its practitioners come from an incredible diversity of backgrounds and hold an equally diverse set of skills. Despite the complexity presented by a field that combines concepts and skills in software engineering, biology, chemistry, robotics, and robotic process automation (RPA), only one graduate program exists for it. Automation engineers are the bridge between the gap that separates the implicit world of the scientist and the explicit world of the robot. To understand their importance, you must understand how wide this gap really is.
A human scientist can adapt and make decisions in real time with little cognitive effort. Scientific protocols may be fixed ahead of time, but scientists still are making many small decisions in the moment as they work even if they are unaware of it. As they pipette some DMSO media or a SYBR green stock, they intuitively adjust the speed and pressure of their thumb on the plunger to account for liquid properties like viscosity and to avoid bubbles. They can tilt the angle of their tips to target small remaining volumes adhering to the edge of a well, watching with their eyes to see if they’ve succeeded and check if there is air in their tip. A biologist doesn’t need to know what height in millimeters they are aspirating from to remove their supernatant without disturbing the pellet and they don’t have to plan how many tips and channels they will use for each individual transfer and if all those tips will fit on deck. If their trough runs out of buffer while aliquoting, they can always pour out more.
All of this is ordinary lab work. While the physical labor is exhausting and time-consuming, none of these implicit decisions feel tiresome. Unfortunately, a robot does not have the luxury to use judgment and all dependencies and edge cases must be foreseen and encoded into an automated method in advance. It lacks the intuition that the scientist relies on.
So, the automation engineer must work with scientists to bring the instructions they seek to automate to a lower level of abstraction and make any implicit instruction, explicit. This process is often iterative, as it involves moving instructions to a lower level of abstraction under constraints that scientists don’t often understand. This process of translation can take weeks for a single experiment, and even months for more comprehensive workflows.
Why go through weeks or months to automate the experiment, when a few days of manual labor achieves the same result? If you had a lot of near-identical experiments to automate (such as running a diagnostic PCR in a COVID-testing lab), it would make sense to spend the months configuring the automated workflow to save the years of manual labor that would otherwise be required. This is where automation sits today - a high activation energy restricts its use cases to low-mix, high-volume work.
If there is utility in fully autonomous biology research, it cannot be realized for a simple reason: the robots won't run. Papers that have explored the concept of embodiment show that models struggle to use lab automation just as much as scientists do1. What can be done to bring automation from the level of abstraction it sits at today, the automation engineer, to the scientists?
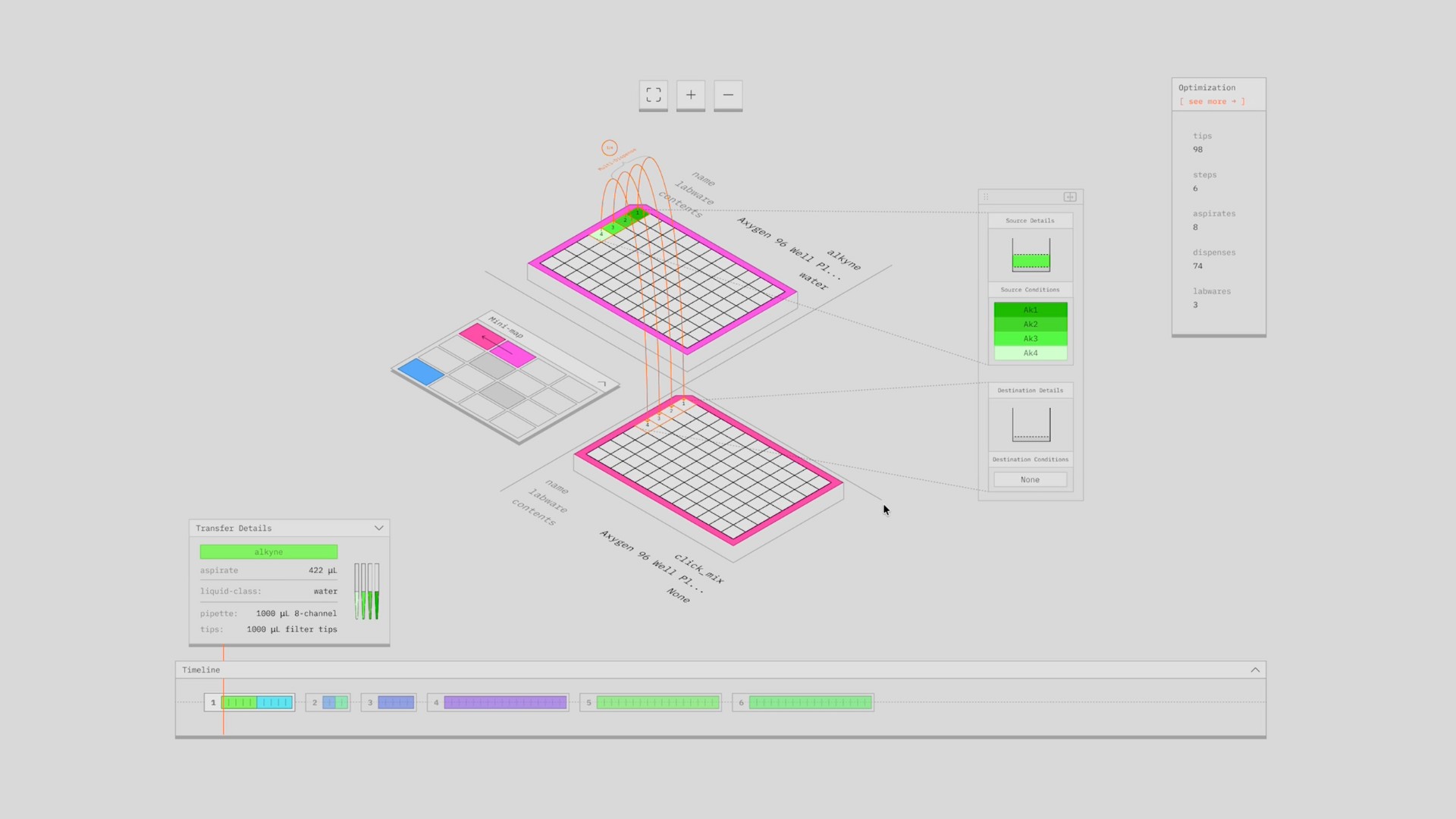
ResearchOS
The central design claim behind ResearchOS is that lab automation should be treated as compilation. A scientist should express intent in a protocol language aligned with how experiments are actually designed and evaluated, and the system should compile that intent into executable robotic code while managing the operational complexity internally. The system must also keep that complexity visible and editable, because trust, iteration, and validation are non-negotiable in wet lab work. While language models have utility as a part of a larger solution, the requirements for interpretability and deterministic and configurable optimization required by this problem make them a poor solution when standing alone. Compilation meets these requirements.
Language models are useful for ingesting unstructured protocol sources (papers, kit manuals, SOPs) and for interactive elicitation of missing context. They are not efficient solvers for deterministic, coupled planning problems like deck layout, dispense strategy selection, scheduling, or tip optimization. Those problems need explicit algorithms and cost models, with ML used to infer context and priors when the required information is not available explicitly. The utility of language models is this: context. This is the missing piece that was not there before, that is now. LLMs are not the solution to the problem of lab automation, but rather the solution to the problem of end-users needing to be fluent in a domain-specific language (the interface between an end-user and a compiler) and the problem of context.
The end result is ResearchOS. It combines our proprietary compiler with a model capable of converting written language into the DSLs our compiler communicates in. It is a system that operates at the level of abstraction of the scientist, but with the computational power and deterministic nature of a powerful in silico problem solving machine: the compiler. It mirrors the evolution of tooling in a plethora of other fields, from CNC machining to data storage. Here's a first look at it:
https://youtu.be/vbFJ3xAYhMU
Final Words
We've failed a lot. Over these two years, we have learned an immense amount about both how best to achieve high-mix automation and what its utility is. We didn't always think this way- in fact, our growth over the past two years mirrors the growth and narrative shift of groups emerging recently in this space. Some of this can be seen in our first public blog post, from Nov. 2024. The growth we have experienced was only made possible through endless iteration with our pilots and endlessly tiring those around us with questions. There are few in the space who we have not badgered with questions. There is so much more to learn. Thank you for letting us bother you.
Despite the premise of our work in streamlining one of the key processes automation engineers are involved in, we are optimistic about the future of the automation engineering profession itself. There will be more automation, because there will be more use cases for automation. We are incredibly grateful for the support we've received from the automation engineering community and have done our best to return it. We are proud to sponsor labautomation.io, labautowiki.org, and lab automation hackathons with groups like Studio45. There will need to be a new generation of young talent thinking about lab automation as it takes center stage in the battle to progress science against existential challenges.
For those interested in helping us progress our work, we are opening a waitlist for a select number of new pilots as we begin our next major iteration of the software. Whether you are at a small biotech company, an academic lab, or at a larger organization, we would be interested in helping to provide you with the mechanical brawn to your squishy brains. You can indicate your interest in pilot partnership here. Do you think we are wrong about something? Please reach out to tell us what, and we will hopefully both learn something.
There is no future for autonomous science without automation.