
A repeating history of automation, abstraction, and misplaced skepticism; the same objections on different hardware. Lab automation is next in line.
Histories of the ‘compiler-like’
High level domain specific languages are everywhere. High level DSLs are programming or specification languages that are specifically designed to express the concepts of that particular domain. Yet, “high level” can come with a bad connotation. To domain experts, “high-level” usually implies forfeiting precision. There are many fields that improved their capabilities through designing high-level abstractions and compilers, but each faced cultural resistance like lab automation faces now, and we can learn from them.
Historically, across many of these industries, the first attempts at abstraction were met with objections – ‘that their domain was too contextual’, ‘that automated optimizers would never achieve parity with expert judgement’, and ‘that high level languages would obscure necessary control needed for flexibility’. Sidenote: If you find yourself thinking “these aren’t really compilers”, I suggest you read my blog on my taxonomy of compilers!
Grace Hopper – developed the first compiler and machine independent programming language
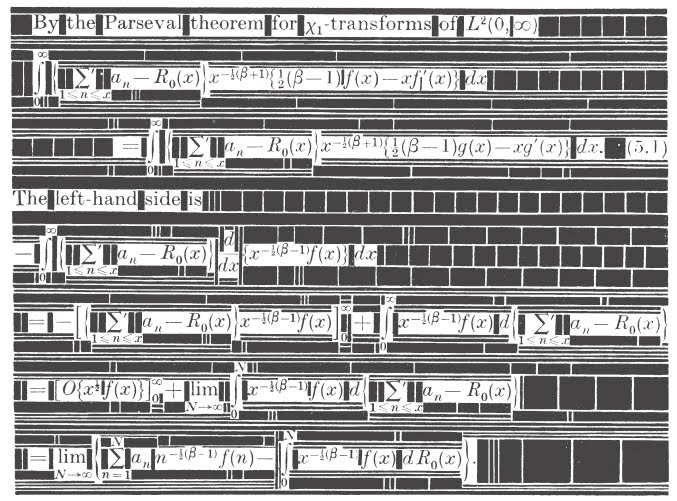
“I had a running compiler and nobody would touch it. They told me computers could only do arithmetic.”
Lynn Conway – pioneer in computer architecture, VLSI design, and design automation
“Critics in the competing Computer Science Lab (CSL) looked askance at what they saw as our ‘toy’ designs and ‘toy’ design tools… they questioned what our tiny effort could possibly bring to the huge semiconductor industry.”
“Experts at various levels of abstraction began having allergic reactions: when seen from the viewpoint of each narrow abstraction our stuff looked far too crude and naive to possibly work.”
Michael Stonebraker – Turing Award-winning database researcher and advocate for SQL
“I can remember a debate in the ’70s: assembly language jockeys would say C is too slow. I need to control my own registers… You should not bet on low-level database repositories by alleging they are faster than a higher-level language.”
It only makes sense, after all, fields like databases, manufacturing, chip design, graphics, and networking are complex nuanced domains that experts spent their lives learning the engineering skills for. Still, eventually databases got SQL, manufacturing got CNC and then CAD, chip design got hardware description languages, graphics pipelines got shader languages, and networks got routing protocols. And in the end, formalizing usable high level abstractions achieved new scale and flexibility in each of these fields.
The canonical example is the compiler itself.

Early computing involved massive mainframes operated by specialists. They were powerful, but changing what they did required intricate engineering work and extensive validation. For some time, the path to more capability seemed to be building even larger, more elaborate machines with more specialized processes, but the important breakthroughs were all abstractions: operating systems, compilers, time-sharing, interactive terminals, graphical interfaces, and languages like FORTRAN and C that let you express computation in terms closer to human thought.
Modern compilers optimize better than humans can by hand, they explore search spaces too large for manual consideration, making tradeoffs between speed, memory, and power consumption that would take a person weeks to evaluate. But in the 1950s and 60s, the idea that an automatic system could match hand-written machine code seemed absurd to many of the experts in computing. Look at where we are now.

I’ve seen roughly seven varieties of obstacles that abstractions faced in the historical accounts of these fields.
- Cultural resistance to compilers and optimizers in favor of expert written programs
- Skepticism over if its technologically feasible, frustration with hype and utopianism
- Resistance rooted in appreciation of the artform of the artisan implementation engineer
- Ironic moralistic pushback to reduced labor needs, despite the hardware platforms already being automation tools
- Doubt that automatized/computerized approaches will be economically viable or beneficial
- Conflation of automation/abstraction with high scale mechanization, attempts at automation that come with versatility regressions
- Frustration with performance and quality of early compilers
- Lack of trust, transparency, and difficult verification of result correctness
- Competition affecting adoption rates of high level languages and infighting over the ‘correct abstractions’
- Navigating standardization vs specialization and the resulting scope of languages for domains with poor universal primitives or rapidly changing and nonstandardized hardware
- Ingrained preferences by implementation experts for imperative languages over declarative languages complicating domain modeling
While compilers, optimizers, and high level languages have ushered in prosperity for so many industries, it was not without growing pains. We can learn a lot from the bumps in the road that these historically parallel domains faced. High level does not actually have to mean forfeiting precision. I love Dijkstra’s quote, “The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise.” Getting this right is democratizing and opens up the possibilities for reasoning about problems that would be otherwise incomprehensible at a lower level.
A favorite case study: digital typesetting & LaTeX
I love reading about these historical, parallel stories of automation and abstraction – it’s delightfully uncanny to hear the same arguments I hear today in lab automation perfectly mirrored. The one that I have been coming back to a lot recently is that of digital typesetting.
I plan to do one other short case study in a future blog about expressivity in domain modeling, but I think this is a particularly illustrative example because like lab automation it is a field where skepticism came from both outsiders and insiders. To the outside the translation barrier and optimization demands were overlooked meaning the skepticism took the form of doubting that abstractions, algorithms, and compilation is necessary and from the inside skepticism took the form of doubting versatile, reliable compilation was even feasible at all.
Typesetting is the layouting of a document – the line length, leading, justification, ligatures, hyphenation, margins, font sizes, symbols, and page breaks – everything on top of text content that is needed to print it. By the late 1960s, typesetting had already gone through a hardware revolution, machines like the Linotron phototypesetter could automatically reproduce type with throughput far beyond manual typesetting. For the first time you could program printing and it was reproducible, precise, and faster than ever previously imagined.


And yet, widespread adoption took another two decades. From the vantage point of someone who grew up with modern printing, this seems bizarre at first. If you had the hardware that could print anything (and do it at scale) why wasn’t it used for everything?
What wasn’t solved was the input problem: How do you describe a page precisely enough that a machine can reproduce it?
The people programming these phototypesetters had to specify where every character went, how wide it was, how it interacted with neighboring characters, and how these local decisions propagated up through words to lines to paragraphs to columns to pages. On top of that, programs were written for high-throughput batches, which made testing slow and expensive and changing a margin width or adding a couple words could cause changes that invalidated entire document layout decisions and required complete recomposition.
Here you can see a description of the involved algorithms that went into one of the early attempts at more algorithmic photocomposition, System 70. This was a step away from positional keyboarding where the operator had to encode the physical layout of the output alongside the input record and still its complexity meant its only users were trained keyboard operators and specialized programmers.


In short, the early days of digital typesetting was slow work done by highly skilled experts, where programs were brittle and programmed typesetting was reserved for low-mix production scale printing efforts. Sound familiar?
The 1968 NBS proceedings on computer typesetting caught this moment perfectly. You can really feel the tension between excitement about what the hardware could do and frustration with the usability and quality of early attempts at layouting automation. The proceedings themselves, ironically but tellingly, noted in their introduction: “Although these proceedings deal with radically new printing techniques, they were produced by conventional methods…”
It’s an interesting mix with companies advertising their newest technical developments in automating typesetting, paired alongside the ominous opening welcome by John Eberhard, quoting an ancient Chinese philosopher, “Whoever uses machines does all his work like a machine… he who carries a heart of a machine in his breast loses his simplicity. It is not that I do not know of such things; I am ashamed to use them.” Eberhard isn’t condemning the use of machines for printing here (that’d been happening since the 1400s), but the use of machines for what he saw as design work – computerized typesetting, electronic composition, and algorithmic layouting.
William Lamparter from Battelle Memorial Institute critiques of digital typesetting on the other hand were largely economic arguments. He wrote, “The road to computerized composition is difficult and, despite manufacturers’ claims and glamour talk to the contrary, much pain, blood, sweat, and tears are necessary to put computerized composition on an economical basis.”
Publishers indicated plans to use computerized composition but “are extremely reluctant to commit a specific piece of work.. object[ing] that the initial typesetting job for a publication like a catalog or a dictionary is almost inevitably more expensive when done by computer”. Lamparter detailed the operational problems he saw to be the cause of this: “maintenance costs and equipment downtime” exceeded expectations, software that “frequently leaves much to be desired,” and specialized work that required “substantial programming capabilities”.
Though perhaps my favorite quote from Lamparter is, “Unfortunately, at this point in time, the picture of push-button ease is punctured with pain and sweat necessary to get the ‘blankety-blank computerized monster’ to do anything well and right and, for our profit-oriented commercial printer and publisher, to do it economically”. The exasperation truly rings so familiar to my ears.
Aside from economic costs, the integrity of the typesetting was in question too. It’s easy to take for granted how significantly poor layouting and “rivers of white space” from poor wordspacing can affect the legibility of a document, but often early digital typesetting simply wasn’t good enough. William R. Bozman from the Inorganic Materials Division at NBS documented the trade-offs of these phototypeset publications noting “substandard quality, having nonstandard symbols, inferior typography, and poor readability. Often these publications have been quite bulky, requiring more paper, more printing press and binding labor, more bookshelf space to store, and greater shipping cost”. These machines could print perfectly and repeatedly, but only if also cleverly and carefully programmed.
Even the success stories of the NBS conference proceedings like that of John J. Boyle at the U.S. Government Printing Office, came with caveats stating, “It would be nice to say we had no trouble in converting these jobs to computer photocomposition but that wouldn’t be very interesting. Actually, from the time of the initial study and decision to proceed, it was nearly one year before we were in full production… [the] programming is very complex, and a major investment in writing of programs is required.”
Skilled operators could produce beautiful work given the time, but they couldn’t yet scale to diverse, small-batch work and the problems described in 1968 weren’t going to be fully solved by incremental improvements in phototypesetters or faster computers. The sentiment expressed by many authors at the conference was that even as technology advanced, there would always be some typesetting that could not be composited digitally.
Progress towards a solution came about a decade later when Donald Knuth, frustrated by the unique difficulty of typesetting mathematics publications, looked towards declarative abstractions. Knuth’s innovation was TeX, the precursor technology to LaTeX. In TeX users could typeset documents by declaratively specifying how they wanted their margins, justifications, and formula to look, and the compositing and layouting would be automatically optimized. The typesetting implementation was abstracted to the compiler.

Later “what you see is what you get” systems like those from Xerox took a parallel approach for everyday printing. The complexity was hidden differently, but still the input problem was still solved by letting users work at a higher abstraction level, working in and evaluating their work in a visual domain unconcerned with the underlying constraints and optimizations being performed on the computer. The abstraction has been so successful that we have forgotten these complex dynamic layouting algorithms even exist.

If you’ve read my blogpost on versatility, flexibility, and programmability, you will notice that the development of markup languages and WYSIWYG visual document editors did not remove versatility. Printing was made usable by moving away from mechanization and towards automated programming, towards abstraction and towards compilers.
The story of raising abstractions continues even today. OpenAI recently released Prism, a tool for scientists to convert natural language into formatted documents. Even though we now have abundant pixel-level training data of what typeset documents look like and even though neural networks can be trained on pixel prediction, their solution is not for a VLM to spit out pixel buffers and generate raster pdfs. Instead Prism has these LLMs convert your natural language requests and diagram doodles into LaTeX and TikZ. Then of course, that output will be deterministically compiled into pixels on your screen.

Why? Because LLMs are good at translating, not compiling. This means converting between representations at very similar abstraction levels: fuzzy natural language into precise formal syntax. This way you let the LLM be the transpiler and don’t throw out the high level languages and compilers. We already have excellent hardware, primitives, and abstractions for typesetting (and for lab automation as well). It’s not just a matter of ‘will the LLM get better at reasoning over time’ or ‘saving money on tokens’, it’s solving language problems with language solutions and deterministic problems with deterministic solutions. This way you get better, more reliable results, more transparency into the black box, and more fluent editing.
Lab automation needs its TeX moment. We are stuck in the era of lab automation systems, like early digital typesetting, that expose too much of the machine. Successful abstraction might come with some growing pains, but rejecting it locks us into a local optimum where we can effectively scale machines, but we cannot scale the expertise of lab automation engineers. Our goal at Tetsuwan is to raise the level of description until scientists can be exact about what they want, and let machines handle the rest.